日志采集系統架構詳解 數據處理與存儲服務的設計與實踐
在當今數據驅動的時代,日志作為系統運行狀態、用戶行為和安全事件的關鍵記錄,其價值日益凸顯。一個高效、可靠的日志采集系統,尤其是其數據處理與存儲服務層,是挖掘日志價值、保障業務穩定與驅動智能決策的核心基礎設施。本文將深入探討日志采集系統中數據處理與存儲服務的架構設計、關鍵技術與實踐考量。
一、數據處理與存儲服務的核心定位
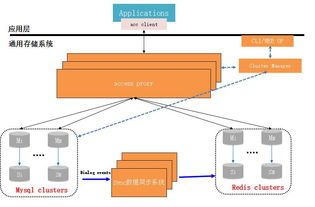
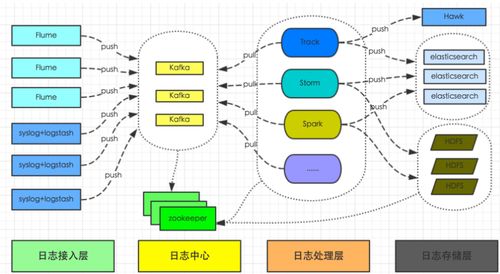
數據處理與存儲服務是日志采集流水線的“中樞大腦”,位于日志采集 Agent(如 Filebeat、Fluentd)之后,可視化與分析平臺之前。它主要負責兩大部分:
- 數據處理:對原始日志進行實時清洗、解析、富化、過濾、聚合與轉換,將其從非結構化或半結構化文本,轉化為便于分析和存儲的結構化數據。
- 數據存儲:提供高吞吐、低成本、可擴展的持久化存儲方案,并支持高效的檢索與分析查詢。
二、典型架構分層與組件
一個成熟的架構通常呈現分層解耦的特點:
1. 消息隊列/流處理緩沖層
- 角色:承接采集端的海量數據流,實現生產者與消費者的解耦,提供流量削峰、緩沖和可靠傳遞保障。
- 技術選型:Apache Kafka、Apache Pulsar、RocketMQ。Kafka因其高吞吐、分布式和持久化特性成為主流選擇。
2. 實時流處理層
- 角色:從消息隊列中消費數據,進行實時的清洗、解析(如正則解析、Grok、JSON解析)、字段提取、格式標準化、敏感信息脫敏、日志分類等。
- 技術選型:Apache Flink(提供精確一次語義、復雜事件處理)、Apache Spark Streaming、或基于 Logstash 的管道。Flink在狀態管理和實時計算方面優勢顯著。
3. 存儲與索引層
- 角色:長期存儲處理后的日志數據,并建立索引以支持快速檢索(全文搜索、字段過濾、范圍查詢等)。
- 技術選型:
- 全文搜索引擎:Elasticsearch(最流行),提供近實時搜索與強大的聚合分析能力。通常與 Kibana 構成 ELK 棧。
- 時序數據庫:如果日志帶有強時間序列特征(如指標型日志),可選用 InfluxDB、Prometheus(更適合監控指標)或 TDengine。
- 低成本對象存儲:對于需要長期歸檔或冷數據,可將數據轉存至 S3、OSS、HDFS,結合 Elasticsearch 的“熱-溫-冷”架構控制成本。
4. 元數據管理與服務層
- 角色:管理日志的元信息,如日志源(Source)、模式(Schema)、解析規則、存儲策略、生命周期(TTL)、權限等。可基于配置中心(如 Apollo、Nacos)或數據庫實現。
三、數據處理的關鍵流程
- 解析與結構化:這是將原始文本轉化為信息的關鍵。例如,使用 Grok 模式將一行 Nginx 訪問日志解析出
client<em>ip、timestamp、method、url、status、response</em>time等字段。 - 數據富化:通過查詢外部數據源(如CMDB、用戶數據庫、IP地理信息庫)為日志記錄添加上下文信息。例如,將 IP 地址富化為地理位置、業務部門。
- 過濾與路由:丟棄無用的調試日志或將不同類型的日志(如應用日志、訪問日志、錯誤日志)路由到不同的 Kafka Topic 或下游存儲索引中。
- 聚合與計算:在流處理中實時計算指標,如每分鐘錯誤數、接口平均響應時間、獨立訪客數(UV)等,并將結果寫入時序數據庫供監控告警使用。
四、存儲方案的設計考量
- 性能與成本平衡:采用分層存儲策略。
- 熱數據:近期高頻查詢的數據(如過去7天),存儲在 SSD 支持的 Elasticsearch 集群中,保證查詢速度。
- 溫/冷數據:歷史數據(如7天前),可轉移到成本更低的機械硬盤 Elasticsearch 節點,或轉儲到對象存儲,通過 Elasticsearch 的 ILM(索引生命周期管理)或 Catalog 服務(如 Apache Hive)進行查詢。
- 可擴展性:存儲系統必須能水平擴展以應對數據量的增長。Elasticsearch 通過分片(Shard)機制實現。
- 可靠性:通過副本(Replica)機制防止數據丟失。對象存儲本身通常提供高耐久性。
- 查詢靈活性:根據查詢模式選擇存儲。詳單式查詢用 Elasticsearch;固定模式的時間范圍聚合分析,可考慮物化視圖或預聚合后存入 ClickHouse 等 OLAP 數據庫。
五、實踐建議與挑戰
- 標準化與契約:推動應用日志輸出標準化(如 JSON 格式),并定義清晰的日志 Schema,能極大降低后期解析的復雜度。
- 監控與治理:對整個數據處理管道(隊列堆積、處理延遲、錯誤率)和存儲集群(磁盤使用率、查詢延遲、節點健康)進行全方位監控。
- 安全與合規:確保日志中的敏感信息(用戶ID、手機號)在存儲前已脫敏或加密,并設置嚴格的訪問控制。
- 挑戰應對:
- 數據爆炸:通過采樣存儲非關鍵日志、合理設置日志級別來控制數據量。
- 解析復雜度:對于格式多變的日志,可采用機器學習輔助的日志解析方案。
- 運維復雜性:考慮使用全托管的云服務(如阿里云 SLS、騰訊云 CLS、AWS OpenSearch)來降低自維護成本。
###
數據處理與存儲服務是日志采集系統從“數據收集”邁向“價值洞察”的橋梁。一個優秀的架構需要在吞吐量、延遲、成本、可靠性和查詢能力之間取得精巧的平衡。隨著云原生和 Serverless 技術的發展,日志處理架構正朝著更彈性、更智能和更集成的方向演進。設計者應緊密結合自身業務規模、技術棧和團隊能力,選擇最合適的組件與架構模式,構建穩定高效的數據地基。
如若轉載,請注明出處:http://m.haybg.cn/product/48.html
更新時間:2026-01-06 23:36:21