Facebook圖形數據庫Tao 揭秘數據處理與存儲的革新之路
在當今數據爆炸的時代,傳統關系型數據庫因其固定的表結構和復雜的關系映射,在處理海量、高度關聯的社交網絡數據時常常顯得力不從心。Facebook作為全球最大的社交平臺,每天需要處理數以千億計的查詢和更新操作,其核心數據模型——用戶、頁面、照片、評論及其之間錯綜復雜的“點贊”、“關注”、“分享”關系——本質上是一個巨大的圖。為了應對這一挑戰,Facebook設計并開發了名為“Tao”的分布式圖形數據庫系統,它專為處理海量社交圖譜數據而生,深刻挑戰了傳統關系型數據庫的統治地位。
一、Tao的誕生背景與核心目標
傳統關系型數據庫(如MySQL)在Facebook早期發揮了重要作用。隨著用戶量和數據關系的指數級增長,其局限性日益凸顯:多表關聯查詢性能低下、難以水平擴展、模式變更成本高昂。社交圖譜數據是典型的圖數據,查詢模式往往圍繞實體(節點)和關系(邊)展開,例如“查找某個用戶的所有朋友”或“查找兩張照片的共同點贊者”。這些操作在圖數據庫中可以被高效地建模為圖的遍歷,而在關系型數據庫中則需要多次的表連接,效率低下。
Tao的核心目標非常明確:為Facebook的社交圖譜數據提供一個高吞吐、低延遲、強最終一致性且能實現全球規模擴展的數據訪問層。它不是一個通用的數據庫,而是一個高度定制化、針對“讀多寫少”的社交圖譜訪問模式進行深度優化的專用系統。
二、Tao的架構揭秘:分層設計與數據模型
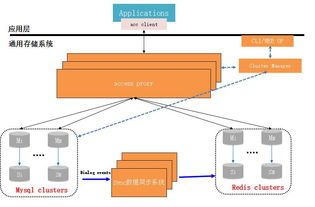
Tao采用經典的分層架構,將邏輯與物理存儲分離:
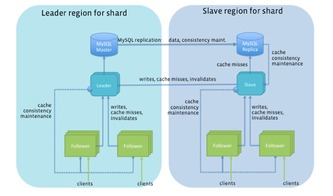
- 客戶端層與緩存層:這是Tao性能的關鍵。每個數據中心的Tao系統都包含一個龐大的多層緩存結構。前端服務器上的Tao客戶端庫會首先查詢本地內存緩存,如果未命中,則請求該數據中心的Tao緩存服務器。緩存中存儲了最熱門的對象(節點)和關聯列表(邊)。這種設計使得絕大多數讀取請求(超過99%)根本無需觸及后端數據庫,從而實現了驚人的低延遲和高吞吐。
- 持久化存儲層:緩存的后端是持久化存儲,Facebook選擇了經過深度修改的MySQL作為“源 of truth”。數據被分片存儲在許多MySQL實例中。Tao的數據模型極其簡潔:
- 對象(Objects):即圖的節點,如用戶、頁面、照片。每個對象有唯一的ID、類型和一組屬性(鍵值對)。
* 關聯(Associations):即圖的邊,如“用戶A是用戶B的朋友”。每條邊由源對象ID、目標對象ID、關聯類型和一個時間戳/屬性數據組成。
所有對象和關聯都作為簡單的行存儲在MySQL表中,通過精心設計的主鍵和索引來優化訪問。
- 領導者-追隨者模型與地理分布:為了支持全球用戶,Tao將數據主副本(領導者)部署在一個主數據中心,并在多個從數據中心(追隨者)維護只讀副本。寫入操作被發送到主數據中心,然后異步復制到從數據中心。這種設計犧牲了跨數據中心的強一致性,換來了地理上近距離讀取的低延遲,符合“寫一次,讀多處”的社交模式。
三、對傳統數據處理與存儲范式的挑戰與革新
- 從關系建模到圖建模:Tao將數據建模為首要的“圖”,而不是強行拆分為表和關系。這使得表達和查詢復雜關系變得直觀且高效,直接滿足了社交應用的核心需求。
- 讀寫路徑的極端優化:通過將緩存作為系統的核心,而非數據庫的附加組件,Tao將讀取路徑優化到了極致。它承認了社交數據訪問的高度局部性(少數熱門內容被頻繁訪問),并基于此構建了整個系統。
- 一致性權衡的藝術:Tao明確選擇了最終一致性模型。在跨數據中心的場景下,用戶可能短暫看到過時數據(如剛發布的評論稍后才在另一個地區顯示),但這對于社交體驗來說是可接受的。這種權衡使得系統能夠實現全球規模的擴展和高可用性。
- 專用化而非通用化:Tao證明了在超大規模場景下,針對特定工作負載定制數據存儲比使用通用解決方案更有效。它不做復雜的SQL查詢,不支持跨分片事務,只提供針對圖的原子操作(如
assoc<em>add,assoc</em>get),從而實現了極致的簡化和性能。
四、影響與啟示
Tao的成功運行(高峰期每秒處理數十億次查詢)不僅支撐了Facebook的核心業務,也為整個行業處理圖數據提供了寶貴范式。它啟示我們:
- 在面對特定領域的海量數據時,可以且應該設計領域專用的存儲系統。
- 緩存是提升大規模系統性能的利器,可以提升到架構的核心地位。
- 在可擴展性、性能和一致性之間做出明智的權衡是分布式系統設計的關鍵。
雖然Tao是Facebook內部系統,但其設計理念深刻影響了后續許多開源圖形數據庫(如JanusGraph、Nebula Graph)和商業服務的發展。它標志著數據處理與存儲服務從“一刀切”的關系型模型,向著多樣化、場景化、深度優化的新時代邁進。在圖形數據日益重要的今天,Tao的揭秘為我們理解如何構建下一代數據基礎設施提供了至關重要的藍圖。
如若轉載,請注明出處:http://m.haybg.cn/product/63.html
更新時間:2026-01-06 10:32:04