構建基于MySQL與Redis的統一KV存儲服務 架構設計與實踐
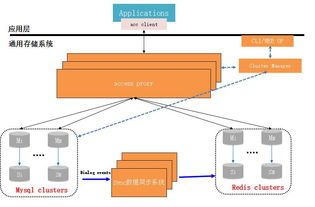
在當今數據驅動的應用場景中,KV(Key-Value)存儲服務因其高效、靈活的特性而被廣泛采用。單一的存儲引擎往往難以滿足所有業務需求。本文將探討如何結合MySQL的關系型數據管理能力與Redis的高性能內存存儲,構建一個統一、可靠且高效的KV存儲服務。
一、架構設計核心理念
統一KV存儲服務的核心在于分層存儲與智能路由。我們將數據按訪問模式分層:
- 熱數據(高頻訪問):存儲在Redis中,利用其內存讀寫優勢,提供亞毫秒級響應。
- 冷數據/全量數據:存儲在MySQL中,作為持久化層,確保數據的可靠性與一致性。
架構組件包括:
- 統一訪問層(Gateway):接收客戶端請求,根據Key進行路由決策。
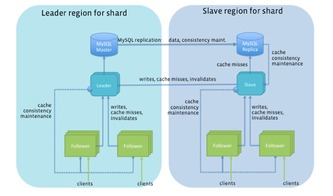
- 緩存層(Redis):集群部署,采用主從復制與哨兵模式(或Redis Cluster)保障高可用。
- 持久層(MySQL):采用分庫分表策略(如基于Key哈希),支持水平擴展。
- 數據同步組件:實現MySQL與Redis之間的數據一致性同步。
二、關鍵技術實現
- 路由策略:在Gateway中維護路由表或使用一致性哈希算法,將Key映射到對應的Redis或MySQL節點。對于寫操作,可先寫入MySQL,再異步更新Redis;對于讀操作,優先查詢Redis,若未命中則穿透至MySQL并回填Redis。
- 數據同步機制:
- 寫操作:采用雙寫策略,客戶端同時寫入MySQL和Redis(或先寫MySQL,通過Binlog監聽異步更新Redis)。為減少延遲,可引入消息隊列(如Kafka)解耦。
- 數據一致性:通過版本號或時間戳解決并發沖突。對于強一致性場景,可使用分布式鎖(如基于Redis的RedLock)保證原子性。
- 緩存失效:設置合理的TTL,并結合主動淘汰策略(如LRU)。當MySQL數據更新時,通過觸發器或監聽Binlog(如使用Canal)來失效或更新Redis中的對應Key。
- 容災與擴展:
- Redis層:采用集群模式,分片存儲數據,并配置持久化(AOF/RDB)防止內存數據丟失。
- MySQL層:使用主從復制,讀寫分離提升吞吐量。對于海量數據,可借助中間件(如MyCat或ShardingSphere)實現自動分片。
- 服務降級:當Redis故障時,Gateway可自動降級,直接訪問MySQL,保障服務可用性。
三、數據處理流程示例
以用戶信息存儲為例:
- 寫入:客戶端調用
set(user<em>id, user</em>info),Gateway將數據寫入MySQL主庫,并異步推送至消息隊列;消費者從隊列讀取數據,更新Redis緩存。 - 讀取:客戶端調用
get(user_id),Gateway優先查詢Redis。若命中則返回;若未命中,則查詢MySQL從庫,將結果回填至Redis并設置TTL。
四、優化與監控
- 性能優化:
- Redis使用Pipeline減少網絡往返,MySQL通過索引優化查詢速度。
- 針對熱點Key,在Redis端采用多副本分散壓力。
- 監控指標:實時追蹤Redis命中率、MySQL查詢延遲、同步隊列堆積情況等,并設置告警閾值。
五、挑戰與注意事項
- 數據一致性:在最終一致性模型下,需權衡業務對舊數據的容忍度。
- 成本控制:Redis內存成本較高,需通過數據冷熱分離與壓縮算法(如Snappy)降低開銷。
- 復雜性管理:引入多組件后,運維復雜度增加,需借助容器化(Docker/K8s)與自動化腳本提升管理效率。
基于MySQL與Redis的統一KV存儲服務,通過分層設計充分發揮了各自優勢,既保證了數據持久性,又提供了高性能訪問。在實際落地中,需根據業務特點靈活調整架構細節,并持續優化以實現穩定、可擴展的數據服務。
如若轉載,請注明出處:http://m.haybg.cn/product/60.html
更新時間:2026-01-06 23:31:49