Kafka 數據入湖新范式 告別傳統 ETL 的數據處理與存儲革命
在數據驅動的時代,企業面臨著海量實時數據的高效處理與價值挖掘挑戰。傳統的數據處理流程,尤其是基于批處理的 ETL(抽取、轉換、加載)模式,因其固有的延遲、復雜性和資源消耗,已難以滿足現代業務對實時性、靈活性和成本效益的迫切需求。隨著數據湖架構的普及和流處理技術的成熟,一種以 Apache Kafka 為核心的數據入湖新范式正在興起,它正在重新定義數據處理與存儲的邊界,引領我們告別傳統的 ETL 范式。
傳統 ETL 的桎梏
傳統的 ETL 流程通常是一個周期性、批量的作業。數據從源系統被抽取出來,經過集中式的轉換處理,最后加載到數據倉庫或其它存儲系統中。這一模式存在幾個顯著痛點:
- 高延遲:批量處理意味著數據從產生到可用存在數小時甚至數天的延遲,無法支持實時決策與即時響應。
- 架構復雜:ETL 管道往往由多個獨立、緊耦合的組件構成,開發、運維和變更成本高昂。
- 靈活性差:模式(Schema)變更困難,難以適應快速變化的業務需求。數據處理邏輯一旦固化,調整起來耗時費力。
- 資源浪費:在數據量激增的背景下,周期性全量處理或復雜的增量邏輯可能導致計算與存儲資源的低效利用。
Kafka 數據入湖新范式的核心理念
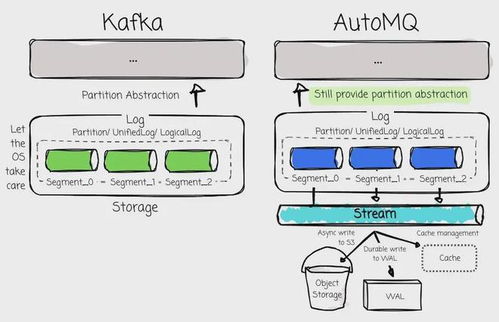
新范式以 Apache Kafka 作為實時數據中樞和流式數據平臺,構建了一條通往數據湖的“高速公路”。其核心轉變在于:從“先存儲,后處理”的批處理思維,轉向“流式優先,實時入湖”的架構。
核心組件與流程:
1. Kafka 作為統一數據入口:所有源頭系統的變更數據(CDC)、應用程序日志、物聯網設備數據、用戶行為事件等,都以流的形式實時攝入 Kafka。Kafka 在此扮演了高吞吐、低延遲、持久化的緩沖區和分發中心角色。
2. 流式處理與輕量轉換:利用 Kafka Streams、ksqlDB 或 Flink 等流處理框架,在數據流動的過程中進行實時的清洗、過濾、富化、聚合等輕量級轉換。這與傳統 ETL 中繁重的、批量的轉換形成鮮明對比。
3. 直接、持續地流入數據湖:經過初步處理的數據流,通過 Connector(如 Kafka Connect 的 HDFS/S3 Connector)或流處理作業本身,以微批或連續的方式直接寫入數據湖(如 Amazon S3、Azure Data Lake Storage、HDFS)。數據以原始或近原始格式(如 Avro、Parquet)存儲,保留了最大的靈活性與保真度。
4. 湖倉一體與后期分析:數據湖成為所有數據的單一事實來源。在此基礎上,可以通過 Presto、Trino、Spark 或云上數據倉庫(如 Snowflake、BigQuery)進行靈活的即席查詢、批處理分析或機器學習。元數據管理(如 Apache Hudi、Delta Lake、Iceberg)確保了數據湖中數據的ACID特性和高效管理。
新范式的優勢
- 極致的實時性:數據從產生到入湖可供分析,延遲可降至秒級甚至亞秒級,真正實現了實時數據湖。
- 架構解耦與彈性:Kafka 將數據生產者與消費者解耦,數據入湖與下游消費(如數據分析、機器學習)成為獨立的、可擴展的環節。系統各組件可以獨立伸縮。
- 簡化數據處理流水線:“流式ETL”或“ELT”(先加載后轉換)模式簡化了管道。許多轉換可以在流中實時完成,更復雜的轉換可以移至數據湖上的計算引擎按需執行。
- 成本效益與靈活性:數據湖存儲成本相對低廉,且支持存儲任意格式的數據。原始數據的保留使得后續可以反復挖掘,無需回溯復雜的ETL流程。
- 更好的數據治理與可觀測性:Kafka 提供了完整的數據流轉軌跡和監控指標,結合數據湖的元數據層,整個數據生命周期的可觀測性和治理能力得到增強。
實踐與展望
這一范式已被眾多互聯網和數字化轉型企業所采用。例如,將數據庫的CDC日志通過 Debezium 接入 Kafka,實時同步至 S3 形成數據湖,并立即用于實時報表、風險監控或特征工程。
Kafka 數據入湖新范式將與云原生、Serverless 計算更深度結合。數據湖與數據倉庫的邊界將進一步模糊(湖倉一體),而 Kafka 作為實時數據流的核心地位將更加穩固。它不僅僅是一個消息隊列,更是構建現代數據架構的基石。
****
告別傳統的、笨重的 ETL,并不意味著放棄數據處理的原則,而是擁抱一種更敏捷、更實時、更經濟的實踐。Kafka 引領的數據入湖新范式,通過將數據流動起來,釋放了數據的即時價值,為企業在數據洪流中保持競爭力提供了強大的架構支撐。這不僅僅是一次技術迭代,更是一次面向未來的數據處理哲學轉變。
如若轉載,請注明出處:http://m.haybg.cn/product/52.html
更新時間:2026-01-06 06:11:49